

目录
快速导航-

综述评论 | 联邦学习中隐私保护聚合机制综述
综述评论 | 联邦学习中隐私保护聚合机制综述
-

综述评论 | 基于区块链的车联网数据共享综述
综述评论 | 基于区块链的车联网数据共享综述
-

多模态大模型发展与应用 | 基于改进型多模态信息融合深度强化学习的自主超声扫描方法
多模态大模型发展与应用 | 基于改进型多模态信息融合深度强化学习的自主超声扫描方法
-

多模态大模型发展与应用 | 基于生成对抗网络与渐进式融合的多模态实体对齐
多模态大模型发展与应用 | 基于生成对抗网络与渐进式融合的多模态实体对齐
-

多模态大模型发展与应用 | 基于特性分流的多模态对话情绪感知算法
多模态大模型发展与应用 | 基于特性分流的多模态对话情绪感知算法
-
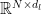
多模态大模型发展与应用 | 面向视觉-语言模型的递进互提示学习
多模态大模型发展与应用 | 面向视觉-语言模型的递进互提示学习
-
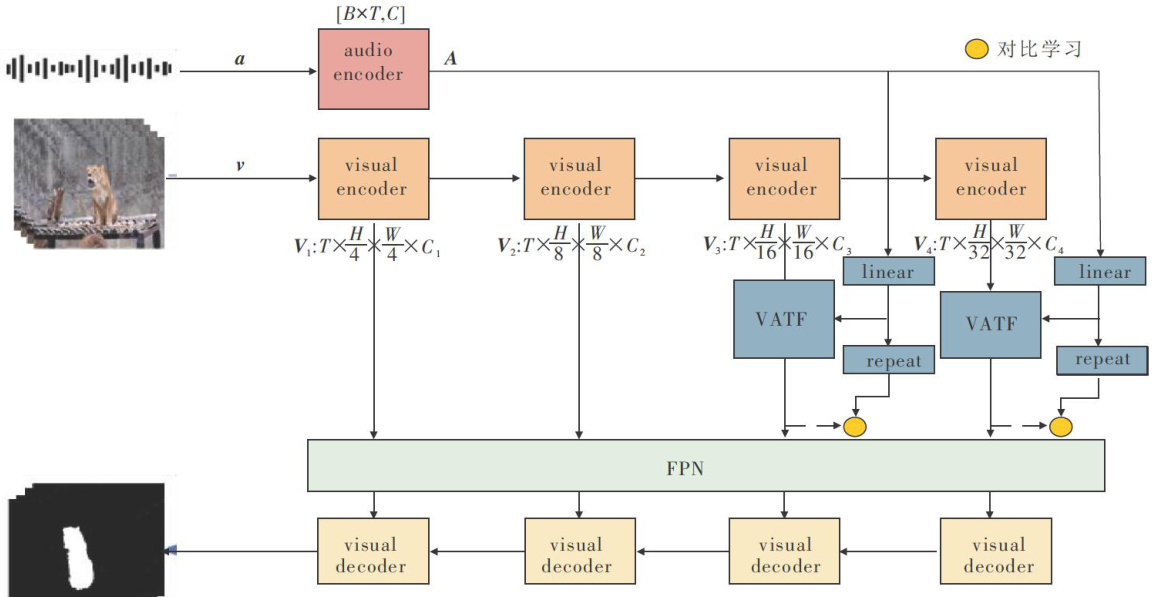
多模态大模型发展与应用 | 多维度交叉注意力融合的视听分割网络
多模态大模型发展与应用 | 多维度交叉注意力融合的视听分割网络
-
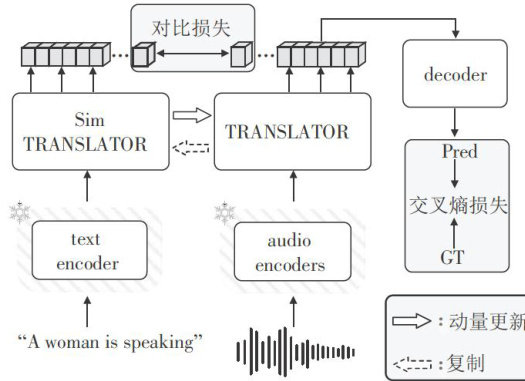
多模态大模型发展与应用 | 基于多模态表征学习的自动音频字幕方法
多模态大模型发展与应用 | 基于多模态表征学习的自动音频字幕方法
-

算法研究探讨 | 基于改进行为克隆算法的机器人运动控制策略
算法研究探讨 | 基于改进行为克隆算法的机器人运动控制策略
-

算法研究探讨 | 基于混合深度强化学习的云制造云边协同联合卸载策略
算法研究探讨 | 基于混合深度强化学习的云制造云边协同联合卸载策略
-

算法研究探讨 | 考虑故障因素的多机器人动态任务分配及路径规划
算法研究探讨 | 考虑故障因素的多机器人动态任务分配及路径规划
-

算法研究探讨 | 基于物理信息强化学习的无人驾驶车辆跟驰控制模型
算法研究探讨 | 基于物理信息强化学习的无人驾驶车辆跟驰控制模型
-

算法研究探讨 | 基于改进多目标鲸鱼优化算法的云制造鲁棒服务组合方法
算法研究探讨 | 基于改进多目标鲸鱼优化算法的云制造鲁棒服务组合方法
-

算法研究探讨 | 基于ABSA与动态少样本提示的主观知识对话回复生成模型
算法研究探讨 | 基于ABSA与动态少样本提示的主观知识对话回复生成模型
-

算法研究探讨 | 改进自适应大邻域搜索算法及其在旅行商问题中的应用
算法研究探讨 | 改进自适应大邻域搜索算法及其在旅行商问题中的应用
-

算法研究探讨 | 基于信息素矩阵优化蚁群算法求解城市建模的旅行商问题
算法研究探讨 | 基于信息素矩阵优化蚁群算法求解城市建模的旅行商问题
-

算法研究探讨 | 融合局部-全局历史模式与历史知识频率的时序知识图谱补全方法
算法研究探讨 | 融合局部-全局历史模式与历史知识频率的时序知识图谱补全方法
-

算法研究探讨 | 一种面向情绪压力分布外检测的多任务跨模态学习方法
算法研究探讨 | 一种面向情绪压力分布外检测的多任务跨模态学习方法
-

算法研究探讨 | 基于句子转换和双注意力机制的归纳关系预测
算法研究探讨 | 基于句子转换和双注意力机制的归纳关系预测
-

算法研究探讨 | 基于多层特征融合与增强的对比图聚类
算法研究探讨 | 基于多层特征融合与增强的对比图聚类
-

算法研究探讨 | 使用NGN算法改进不平衡数值数据的研究
算法研究探讨 | 使用NGN算法改进不平衡数值数据的研究
-

算法研究探讨 | 一种基于终端策略的近似涟漪扩散算法
算法研究探讨 | 一种基于终端策略的近似涟漪扩散算法
-

算法研究探讨 | 融合混合提示与位置感知的突发事件抽取模型
算法研究探讨 | 融合混合提示与位置感知的突发事件抽取模型
-

算法研究探讨 | 面向说话人日志的多原型驱动图神经网络方法
算法研究探讨 | 面向说话人日志的多原型驱动图神经网络方法
-

算法研究探讨 | 邻域变异的黑猩猩多峰优化算法
算法研究探讨 | 邻域变异的黑猩猩多峰优化算法
-

系统应用开发 | 基于增强型差分进化算法求解广义Nash均衡问题
系统应用开发 | 基于增强型差分进化算法求解广义Nash均衡问题
-

系统应用开发 | 面向可重构阵列的CNN多维融合数据复用方法
系统应用开发 | 面向可重构阵列的CNN多维融合数据复用方法
-

系统应用开发 | 一种用于机器声音异常检测的ARViTrans方法
系统应用开发 | 一种用于机器声音异常检测的ARViTrans方法
-

系统应用开发 | 基于数据驱动的WSN故障检测框架
系统应用开发 | 基于数据驱动的WSN故障检测框架
-

系统应用开发 | 一种面向软件众包的众包工人选择模型
系统应用开发 | 一种面向软件众包的众包工人选择模型
-

网络与通信技术 | 边缘计算中动态服务器部署与任务卸载联合优化算法
网络与通信技术 | 边缘计算中动态服务器部署与任务卸载联合优化算法
-

网络与通信技术 | 基于自适应差分进化算法的时间敏感网络流量调度
网络与通信技术 | 基于自适应差分进化算法的时间敏感网络流量调度
-

网络与通信技术 | 基于LCVAE-CNN的多任务室内Wi-Fi指纹定位方法
网络与通信技术 | 基于LCVAE-CNN的多任务室内Wi-Fi指纹定位方法
-

信息安全技术 | 基于多扰动策略的中文对抗样本生成方法
信息安全技术 | 基于多扰动策略的中文对抗样本生成方法
-

信息安全技术 | 基于用户选择的鲁棒与隐私保护联邦学习方案
信息安全技术 | 基于用户选择的鲁棒与隐私保护联邦学习方案
-

信息安全技术 | 云医疗环境下策略可更新的多权威属性基安全方案
信息安全技术 | 云医疗环境下策略可更新的多权威属性基安全方案
-

图形图像技术 | SP-CPGCN:用于尘肺病分期的超像素先验因果感知图卷积网络
图形图像技术 | SP-CPGCN:用于尘肺病分期的超像素先验因果感知图卷积网络
-

图形图像技术 | 基于多级多特征混合模型的白血病亚型自动分类
图形图像技术 | 基于多级多特征混合模型的白血病亚型自动分类
-

图形图像技术 | 结合多尺度特征与局部采样描述的多模态图像配准方法
图形图像技术 | 结合多尺度特征与局部采样描述的多模态图像配准方法
-

图形图像技术 | 迭代伪点云生成的3D目标检测
图形图像技术 | 迭代伪点云生成的3D目标检测
-

图形图像技术 | 分层蒸馏解耦网络的低分辨率人脸识别算法
图形图像技术 | 分层蒸馏解耦网络的低分辨率人脸识别算法
-

图形图像技术 | 基于运动分割的动态SLAM联合优化算法
图形图像技术 | 基于运动分割的动态SLAM联合优化算法
-

图形图像技术 | 基于预测划分卷积神经网络的全景视频快速编码算法
图形图像技术 | 基于预测划分卷积神经网络的全景视频快速编码算法


















 登录
登录